The restriction to the Conjugate Gradient Method and its generalization, considered in the previous page, would highly restrict the field of applicability of such a processor.
This is why we started to study the bounds for other simulation problems. We assume that simulation in the atmospheric physics is among the most complex simulations.
We analyzed the principal parts of the Weather Research & Forecast program (Microphysics Driver, Radiation Driver, and advect subroutines) to find that their arithmetic complexity is not more than about twice that of the HPCG benchmark.
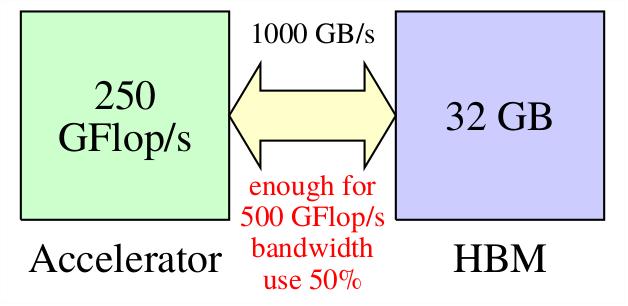
The previous paragraph suggests that the peak performance 250 GFlop/s would be sufficient for a processor of accelerator that is application specific for general supercomputer simulations (CFD, NWP, etc.) and has similar memory bandwidth characteristics like a processor considered in the previous page (i.e., the bandwidth 1000 GB/s, used up to 50 % - the case of the optimal bandwidth use is considered later).
In terms of the recent state-of-the-art, the value 250 GFlop/s seems ridiculous, but remember that the HPCG performance of Nvidia Volta-100 is only slightly above 100 GFlop/s, no matter how high is its peak.
Of course, an acelerator design could not be based on the analysis of the HPCG and the WRF only. It is one of the most important goal of LOWAIN to investigate the behavior of a collection of simulation programs from different fields of physics and technology that is as comprehensive as possible.
Note that the load of the processor-memory interface depends on the cache size - the larger and more efficient is the cache, the lower is the data traffic across the processor-memory interface.
The previous paragraph implies that the standard methods of assessing the arithmetic intensity of a particular program on a particular computer could not be used and a virtual computer with variable cache sizes and some other parameters must be developped. This goal has already been partially achieved for FORTRAN simulation programs; the system has been used for the WRF analysis.
The goal of LOWAIN is not studying the behavior of simulation programs on a particular computer with a given and fixed cache size. The goal is, given a fixed memory bandwidth value, suggesting the optimal computing power and the cache size of a future simulation specific accelerator that represents the optimal trade-off between simplicity and cost on one hand, and wide applicability on the other hand.